- Published on
Relational Database Table Archival
- Authors

- Name
- Shubham Jain
- https://x.com/shubhrjain
This document outlines the steps to archive data on relational database tables. These concepts are generally applicable to all databases but specifically to relational databases and here we will use postgreSQL for demo purposes. Primary goal of archiving data is to make tables lean and lightweight for better performance. For e.g. if there is a part of data that is not accessed at all, you can archive it or even delete it based on your requirements. Archiving/Deletion makes table performant and optimal for their query usages.
If my table is small like some 1000's of rows(MBs in size) then I can pick good time and select all data for archival and store it in csv and then delete from source but tables bigger in size would require careful planning and considerations.
We outline below steps or planning required to achieve table archival.
Setup
- Make sure to have docker and docker compose installed.
- Download the flights demo database from here
version: '3.9'
services:
p1:
container_name: p1
ports:
- "5458:5432"
image: postgres:15.2
environment:
POSTGRES_PASSWORD: local
POSTGRES_USERNAME: local
POSTGRES_DB: demo
volumes:
- ./demo-small-en-20170815.sql:/docker-entrypoint-initdb.d/demo.sql
p2:
container_name: p2
ports:
- "5459:5432"
image: postgres:15.2
environment:
POSTGRES_PASSWORD: local
POSTGRES_USERNAME: local
POSTGRES_DB: demo
volumes:
- ./demo-small-en-20170815.sql:/docker-entrypoint-initdb.d/demo.sql
p3:
container_name: p3
ports:
- "5460:5432"
image: postgres:15.2
environment:
POSTGRES_PASSWORD: local
POSTGRES_USERNAME: local
POSTGRES_DB: demo
volumes:
- ./demo-small-en-20170815.sql:/docker-entrypoint-initdb.d/demo.sql
- start postgres servers
docker-compose up -d
- flights
demodatabase is ready for our exercise. - browse the database and explore the tables
1. Data Archival Filter
We would require a filter to find out required data for archival. For e.g. if we look at the demo table then our filter can archive data older than 5 years. Our filters will depend on the columns provided in the table and requirements for archival. Generally we can depend on following
- Datetime of record(created/updated)
- State of the record For e.g. if you're archiving tokens table then you can archive all expired token so status of token can be used as filter.
2. Observability
Finding out rows which have never been accessed at all and that also belongs in our subset of archival.
3. Deletion/Archival
When we’ve figured out the records for archival, the next step is to soft delete because a very strong reason behind this is database performance. If we are archiving a huge number of records at once and deleting from the source database then it can lead to suboptimal performance of the database. So we should add a column is_deleted and make it true for all the records that are ready for archival. Remember deletion/archival is an operation and it will consume resources on database as you do upgrades or maintenance work on a scheduled timeline which is outside of your ususal business operations and when have least amount of traffic. Deletion/Archival should be treated with same respect.
Reference for Performance Implications : https://medium.com/@kotanjan.neo/archiving-mysql-tables-2d1cc8aea980#:~:text=W,run%20it)
4. Archival Storage
Once we have records for archival identified in the source database then we can proceed to persist them to an archival storage like object storage. Important goal here is to ensure that it is cost effective and it is easy to query the data on demand. Here we've various questions ahead of us
- Class Type of Bucket and Object
- Data Storage format
- Operations on Cloud Storage Object
- Batch or Streaming
4. Postgres Data Cleanup
Once data is archived on cloud storage and set as is_deleted on source database. We can schedule some periodic jobs to clean up data on the source database in small batches.
- Schedule of data cleanup
- Batch size to clean up data
## 5. Ready to Time Travel We can use BigQuery or any other tool locally to query data from archival storage on demand for any compliance queries.
Archival with Partitioning using FDW Demo
In the first demo, we will choose our filter for archival and instead of setting is_deleted flag, we will partition the data. We will update our client queries to route to a partition where hot data resides and then we can archive other partition. We will focus on flights table that stores data of everyday flights.
Setup
We will setup a postgres server with flights demo database of small size to demonstrate this exercise.
Partitioning
Lets select two filters for archival
status = "Cancelled"scheduled_departure < now()::date-365
select count(*) from flights where status = 'Cancelled' and scheduled_departure < now()::date-365;
Partitioning by scheduled_departure
CREATE TABLE flights_latest(flight_id INT, flight_no VARCHAR(6), scheduled_departure TIMESTAMP, scheduled_arrival TIMESTAMP, departure_airport VARCHAR(3), arrival_airport VARCHAR(3), status VARCHAR(20), aircraft_code VARCHAR(3), actual_departure TIMESTAMP, actual_arrival TIMESTAMP);
CREATE EXTENSION postgres_fdw;
CREATE SERVER instance2 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host 'instance2', dbname 'demo', port '5432');
CREATE SERVER instance3 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host 'instance3', dbname 'demo', port '5432');
CREATE USER MAPPING FOR postgres SERVER instance2 OPTIONS (user 'postgres', password 'postgres');
CREATE USER MAPPING FOR postgres SERVER instance3 OPTIONS (user 'postgres', password 'postgres');
CREATE TABLE flights_cancelled(flight_id INT, flight_no VARCHAR(6), scheduled_departure TIMESTAMP, scheduled_arrival TIMESTAMP, departure_airport VARCHAR(3), arrival_airport VARCHAR(3), status VARCHAR(20), aircraft_code VARCHAR(3), actual_departure TIMESTAMP, actual_arrival TIMESTAMP);
CREATE TABLE flights_arrived(flight_id INT, flight_no VARCHAR(6), scheduled_departure TIMESTAMP, scheduled_arrival TIMESTAMP, departure_airport VARCHAR(3), arrival_airport VARCHAR(3), status VARCHAR(20), aircraft_code VARCHAR(3), actual_departure TIMESTAMP, actual_arrival TIMESTAMP);
CREATE FOREIGN TABLE flights_cancelled PARTITION OF flights for values from ('2021-01-01') to ('2021-12-31') SERVER instance2;
CREATE FOREIGN TABLE flights_arrived PARTITION OF flights for values from ('2022-01-01') to ('2022-12-31') SERVER instance3;
Cons
- we can't partition the data based on multiple fields including fields other than timestamp.
Pros
- Native and performant approach to park the unused data into separate partition.
Archival with Partitioning using Inheritance
In the second demo, we will choose our filter for archival and instead of setting is_deleted flag, we will partition the data. We will update our client queries to route to a partition where hot data resides and then we can archive other partition. We will focus on flights table that stores data of everyday flights.
Setup
We will setup a postgres server with flights demo database of small size to demonstrate this exercise.
Partitioning
Let's select two filters for archival
status = "Cancelled"scheduled_departure < now()::date-365
select count(*) from flights where status = 'Cancelled' and scheduled_departure < now()::date-365;
Partitioning by scheduled_departure
-- Step 1: Our original table is flights
-- Step 2: Create the child tables for partitioning
CREATE TABLE flights_arrived_a_year_ago (
CHECK (status = 'Arrived'),
CHECK (scheduled_departure < now()::date-365)
) INHERITS (flights);
CREATE TABLE flights_scheduled_a_year_ago (
CHECK (status = 'Scheduled'),
CHECK (scheduled_departure < now()::date-365)
) INHERITS (flights);
-- Step 3: Create indexes on the child tables if needed
CREATE INDEX idx_flights_data_arrived_scheduled_departure ON flights_arrived_a_year_ago (scheduled_departure);
CREATE INDEX idx_flights_data_scheduled_scheduled_departure ON sales_scheduled_a_year_ago (scheduled_departure);
-- Step 4: Set up a trigger to route inserts to the appropriate child table
CREATE OR REPLACE FUNCTION flights_insert_trigger()
RETURNS TRIGGER AS $$
BEGIN
IF NEW.status = 'Arrived' THEN
INSERT INTO flights_arrived_a_year_ago VALUES (NEW.*);
ELSIF NEW.status = 'Scheduled' THEN
INSERT INTO flights_scheduled_a_year_ago VALUES (NEW.*);
-- Add more conditions for other status if needed
ELSE
RAISE EXCEPTION 'Unhandled status: %', NEW.status;
END IF;
RETURN NULL;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER insert_flights_trigger
BEFORE INSERT ON flights
FOR EACH ROW EXECUTE FUNCTION flights_insert_trigger();
INSERT INTO flights_arrived_a_year_ago
SELECT * from flights where status = 'Arrived' and scheduled_departure < now()::date-365
Cons
- we can't partition the data based on multiple fields including fields other than timestamp.
Pros
- Native and performant approach to park the unused data into separate partition.
Archival with Copying Data to Temporary Table
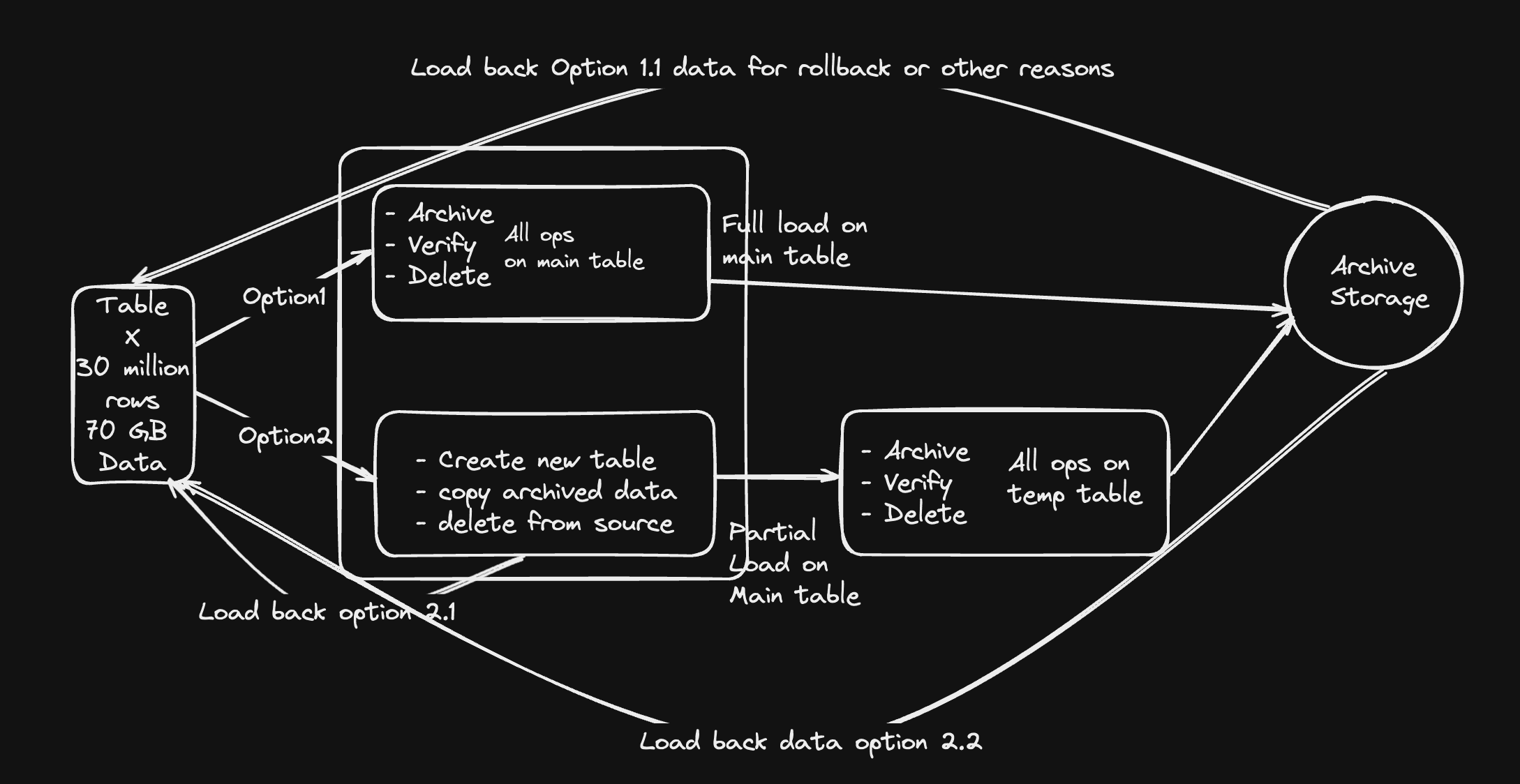
Setup
We will setup a postgres server with flights demo database of small size to demonstrate this exercise.
Deleting from Source and copying to another table
Lets select two filters for archival
status = "Cancelled"scheduled_departure < now()::date-365
\timing on
CREATE TABLE flights_archives AS
WITH moved_rows AS (
DELETE FROM flights f
WHERE status = 'Cancelled' and scheduled_departure < now()::date-365
RETURNING f.* -- or specify columns
)
SELECT * FROM moved_rows;
Verification
| Query | Before | After |
|---|---|---|
| select count(*) from flights; | 33121 | 32707 |
| select count(*) from flights_archives | 0 | 414 |
| select count(*) from flights where status = 'Cancelled'; | 414 | 0 |
Pros
- In case deletion was wrong, rows can be put back into source table.
INSERT into flights
select * from flights_archives;
Cons
- Putting pressure twice for the same thing i.e. deletion.
- First deletion from main table and then deletion of temporary table.
References
MySQL Approaches
- https://stackoverflow.com/questions/46383824/best-way-to-archive-mysql-tables-data-huge-data
- https://stackoverflow.com/questions/36975795/how-to-periodically-archive-data-in-mysql
- https://stackoverflow.com/questions/65093/best-way-to-archive-live-mysql-database
- https://stackoverflow.com/questions/67384988/mysql-best-practice-for-archiving-data
- https://stackoverflow.com/questions/20623529/mysql-table-data-archiving